In this 3 parts post I want to show:
- how standard, out-of-the-box, Scala helped me to code a small application
- how Functional Reactive Programming brings a real improvement on how the GUI is built
- how to replace Parser Combinators with the Parboiled library to enhance error reporting
You can access the application project via github.
I can do that in 2 hours!
That's more or less what I told my wife as she was explaining one small problem she had. My wife is studying psychology and she has lots of essays to write, week after week. One small burden she's facing is keeping track of the number of words she writes because each essay must fit in a specific number of words, say 4000 +/- 10%. The difficulty is that quotations and references must not be counted. So she cannot check the file properties in Word or Open Office and she has to keep track manually.
For example, she may write: "... as suggested by the Interpretation of Dreams (Freud, 1905, p.145) ...". The reference "(Freud, 1905, p.145)" must not be counted. Or, "Margaret Malher wrote: "if the infant has an optimal experience of the symbiotic union with the mother, then the infant can make a smooth psychological differentiation from the mother to a further psychological expansion beyond the symbiotic state." (Malher cited in St. Clair, 2004, p.92)" (good luck with that :-)). In that case the quotation is not counted either and we must only count 3 words.
Since this counting is a bit tedious and has to be adjusted each time she does a revision of her essay, I proposed to automate this check. I thought "a few lines of Parser Combinators should be able to do the trick, 2 hours max". It actually took me a bit more (tm) to:
write a parser robust enough to accommodate for all sorts of variations and irregularities. For example, pages can be written as "p.154" or "pp.154-155", years can also be written "[1905] 1962" where 1905 is the first edition, and so on
use scala-swing to display the results: number of words, references table, file selection
write readers to extract the text from .docx or .odt files
Let's see now how Scala helped me with those 3 tasks.
Parsing the text
The idea behind parser combinators is very powerful. Instead of building a monolithic parser with lots of sub-routines and error-prone tracking of character indices, you describe the grammar of the text to parse by combining smaller parsers in many different ways.
In Scala, to do this, you need to extend one of the Parsers traits. The one I've choosen is RegexParsers. This is a parser which is well suited for unstructured text. If you were to parse something more akin to a programming language you might prefer StdTokenParsers which already define keywords, numeric/string literals, identifiers,...
I'm now just going to comment on a few points regarding the TextParsing trait which is parsing the essay text. If you want to understand how parser combinators work in detail, please read the excellent blog post by Daniel Spiewak: The Magic behind Parser Combinators.
The main definition for this parser is:
def referencedText: Parser[Results] =
rep((references | noRefParenthesised | quotation | words | space) <~ opt(punctuation)) ^^ reduceResults
This means that I expect the text to be:
a repetition (the
repcombinator) of a parserthe repeated parser is an alternation (written
|) of references, parenthetised text, quotations, words or spaces. For each of these "blocks" I'm able to count the number of words. For example, a reference will be 0 and parenthetised text will be the number of words between the parenthesesthere can be a following punctuation sign (optional, using the
optcombinator), but we don't really care about it, so it can be discarded (hence the<~combinator, instead of~which sequences 2 parsers)
Then I have a function called reduceResults taking the result of the parsing of each repeated parser, to create the final Result, which is a case class providing:
- the number of counted words
- the references in the text
- the quotations in the text
Using the RegexParser trait is very convenient. For example, if I want to specify how to parse "Pages" in a reference: (Freud, 1905, p.154), I can sequence 2 parsers built from regular expressions:
val page = "p\\.*\\s*".r ~ "\\d+".r
- appending
.rto a string returns a regular expression (of typeRegex) - there is an implicit conversion method in the
RegexParserstrait, calledregexfrom aRegexto aParser[String] - I can sequence 2 parsers using the
~operator
The page parser above can recognize page numbers like p.134 or p.1 but it will also accept p134. You can argue that this is not very well formatted, and my wife will agree with you. However she certainly doesn't want to see the count of words being wrong or fail just because she forgot a dot! The plan here is to display what was parsed so that she can eventually fix some incorrect references, not written according to the academia standards. We'll see, in part 3 of this series how we can use another parsing library to manage those errors, without breaking the parsing.
One more important thing to mention about the use of the RegexParsers trait is the skipWhitespace method. If it returns true (the default), any regex parser will discard space before any string matching a regular expression. This is convenient most of the time but not here where I need to preserve spaces to be able to count words accurately.
To finish with the subject of Parsing you can have a look at the TextParsingSpec specification. This specification features a ParserMatchers trait to help with testing your parsers. It also uses the Auto-Examples feature of specs2 to use the text of the example directly as a description:
"Pages" ^
{ page must succeedOn("p.33") } ^
{ page must succeedOn("p33") } ^
{ pages must succeedOn("pp.215-324") } ^
{ pages must succeedOn("pp.215/324") } ^
{ pages("pp. 215/324") must haveSuccessResult(===(Pages("pp. 215/324"))) } ^
Displaying the results
The next big chunk of this application is a Swing GUI. The Scala standard distribution provides a scala-swing library adding some syntactic sugar on top of regular Swing components. If you want to read more about Scala and Swing you can have a look at this presentation.
The main components of my application are:
- a menu bar with 2 buttons to: select a file, do the count
- a field to display the currently selected file
- a results panel showing: the number of counted words and the document references
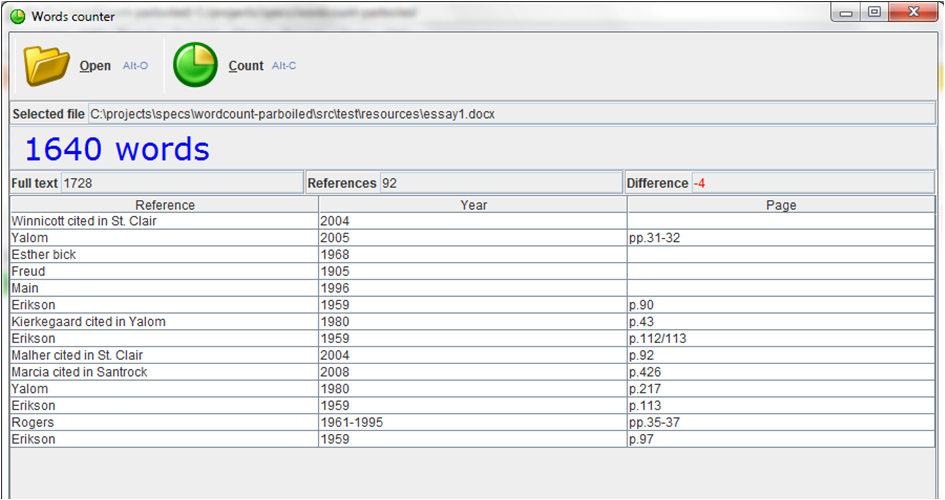
count example, note that the parsing is not perfect since the word counts do not add up!
If you have a look at the code you will see that this translates to:
- an instance of
SimpleSwingApplicationdefining atopmethod and including all the embedded components: a menu bar, a panel with the selected file and results - the subcomponents themselves: the menu items, the count action, the results panel
- the "reactions" which is a
PartialFunctionlistening to the events created by some components,SelectionChangedfor example, and triggering the count or displaying the results
I was pretty happy to see that much of the verbosity of Swing programming is reduced with Scala:
- you don't need to create xxxListeners for everything
- there are components providing both a
Paneland aLayoutManagerwith the appropriate syntax to display the components:FlowPanel,BoxPanel,BorderPanel - thanks to scala syntax you can write
action = new Action(...)instead ofsetAction(new Action(...))
This is nice but I think that there is a some potential for pushing this way further and create more reusable out-of-the-box components. For example, I've created an OpenFileMenuItem which is a MenuItem with an Action to open a FileChooser. Also, something like a pervasive LabeledField with just a label and some text would very useful to have in a standard library.
I also added a bit of syntactic sugar to have actions executed on a worker thread, instead of the event dispatch thread (to avoid grey screens), using the SwingUtilities.invokeLater method. For example: myAction.inBackground will be executed on a separate thread.
Eventually, I was able to code up the GUI of the application pretty fast. The only thing which I didn't really like was the Publish/React pattern. It felt a bit messy. The next part of this series will show how Functional Reactive Programming with the reactive library helped me write cleaner code.
Reading the file
I anticipated this part to be a tad difficult. My first experiments of text parsing were using a simple text file and I knew that having the user (my wife, remember,...) copy and paste her text to another file just for counting would be a deal-breaker. So I tried to read .odt and .docx files directly. This was actually much easier than anything I expected!
Both formats are zipped xml files. Getting the content of those files is just a matter of:
reading the
ZipFileentries and find the file containing the textval rootzip = new ZipFile(doc.path) rootzip.entries.find(_.getName.equals("word/document.xml"))loading the xml as a
NodeSeqXML.load(rootzip.getInputStream(f)))find the nodes containing the actual text of the document and transform them to text
// for a Word document text is under <p><t> tags (xml \\ "p") map (p => (p \\ "t").map(_.text) mkString "") mkString "\n"
For further details you can read the code here.
Recap
That's it, parser combinators + scala-swing + xml = a quick app solving a real-world problem. In the next posts we'll try to make this even better!
6 comments:
Great post! Looking forward to the next installment.
Link to DocReader.scala isn't working. Should be https://github.com/etorreborre/wordcount/blob/master/src/main/scala/docs/DocReader.scala
I fixed it, thanks.
For the ODT format, if you want to have the correct word count, you'll also need the "h" tags for the headings.
Good to know. So far my wife hasn't used headers because I think she's not supposed to.
But your point makes me realize that this bug would not be caught and is not easy to catch.
Really great
Post a Comment